1. Introduction
etwork on Chip (NoC) [1] [2] [3] is the latest approach to overcome the limitation of bus based communication network. NoC is a set of routers employed in a network, in which different nodes are inter connected with their cores can communicate with each others. In a network data comes in packets and sent to the destination with IP via routers and links [4] . When a packet reaches its destination address, it means it is switched [5] to the IP attached to the router. On-chip communications among different networks is possible using interconnection network topology [5] [6], switching, routing, queuing .flow control [11] and scheduling. Research can be done for n-dimensional topological structures network on chip design. The idea of NoC is derived from distributed computing and large scale computer networks. There are different routing techniques used in NOC design considerations to meet high throughput and cover time to market. Due to big constraints on hardware and memory resources utilization, the routing methods for NoC should be very simple.
According to the need of processors, NoC technology gives chip designer's flexibility in choosing the network topology, according to University of Bologna professor Luca Benini, founder of and scientific advisor for iNoCs, a start-up provider of on-chip interconnection technology. High degree of parallelism and pipelining increases [8] [12] the performance of the system because all the links in the network works simultaneously on different data packets [13]. As the complexity of the system is increasing, NOC is the solution to enhance system performance in comparison to the previous technological architectures such as dedicated, wires, point to point, bridges and shared buses. The scalability of system and throughput [17] [20] will increase because algorithms are designed in such a way that it offers higher degree of parallelism. For example, a mesh NoC topology [18] can function with parallelism and thus is well-suited for multiprocessor SoCs, whose cores must run in parallel. Prototype NoCs by the Electronics and Information Technology Laboratory of the French Atomic Energy Commission's Faust, the Swedish Royal Institute of Technology's Nostrum, and the Technion-Israel Institute of Technology's QNoC work with a mesh topology. a) Tools Utilized Design and implementation of mesh network is carried out using Project Navigator ISE 14.2, Xilinx company. It is a tool used to design the IC and to view their RTL (Register Transfer Logic) schematic. Model Sim EE 10.1b student's edition is a tool of Mentor Graphics Company used for simulation and debugging the functionality. The chip implementation is done using VHDL programming language.
The paper is organized as follows: Section I presents the introduction and the tools utilized. Section II describes intercommunication among 2D (8 x 8) mesh networks. Section III describes the FPGA synthesis environment. Section IV describes the Result and Performance Evaluation. Section V presents the Device utilization and timing summary. Conclusion is presented in Section VI.
2. Intercommunication among 2D Mesh Networks
Intercommunication among 2D NOC networks can be understood using arbitration logic selection of networks [12]. First understanding, how a 2D networks behaves, then focusing on the intercommunication among 2D networks. 2D NOC [12] follows the cross link which allows addressing any node at any time [11]. A 2D mesh network is connecting multiple inputs to multiple outputs in a matrix form. The 2D NOC architecture is a m × n mesh of switches [10] and resources are placed on the slots formed by the switches. For an m x n architecture there are m nodes on X axis and n nodes on Y axis respectively. Considering an 8 x 8 structure in which 64 nodes can perform intra communication. Node identification is based on the row address and column address [1]. For example, if row address = 000 and column address = 101, node 6 (N 6 ) is identified. Similarly there is the possibility of identifying any node. Table 1 list the possible node address generation scheme for 2D 8 x 8 structure. Step 2 : reset = 0, same clk is used for synchronization and provide rising edge.
Step 3 : Select the address of destination node Node_address [5:0] of 6 bits for 8 x 8 structure.
Step 4 : Force the value of row_address and column_address of destination node. For 8 x 8 NOC row_address[2:0] and column_address[2:0] are of 3 bits.
Step 5 : Force the value of network address [1:0] of destination network. network_address [1:0] = "00" for network 1, network_address [1:0] = "01" for network 2, network_address [1:0] = "10" for network 2 and network_address [1:0] = "11" for network 3.
Step 6 : Give the eight bit value of data_in. Force write_en =1 and read_en =0 and then run.
Step 7 :
Write_en =0 and read_en =1 and run. Desired output on destination is achieved.
When write_en =1 and read_en =0, the data is written in temp variable from the source node, when write_en =0 and read_en =1, the data is read from the temp variable to destination node. Clk is applied at the Table 3 : Design pins and their functional description for (8 x 8) NOC
3. Pins
Functional Description reset used for synchronization of the components by using clk clk Provide rising edge of clock pulse node_address [5:0] Address of the source and destination node of 6 bits row_address [2:0] represents address of the nodes in x direction (3 bits) column_address [2:0] represents address of the nodes in y direction ( 3 bits) read_en control signal to read data (1 bit) write_en control signal to write data (1 bit) network_address [1:0] Selection logic for the network ( 2 bits) data_in [7:0] represents input data in the network (8 bits) data_out [7:0] represents 8 bit output data of the destination node (8 bits)
IV.
4. Synthesis
The Spartan-3E starter kit [21] [22] provides easy way to test the various programs in the FPGA itself, by dumping the 'bit' file of the designed program in Xilinx software into the FPGA and then observing the output .The Spartan 3E FPGA board [8] comes built in with many peripherals that help in the proper working of the board and also in interfacing the various signals to the board itself. Some of the peripherals included in the Spartan 3E FPGA board include: 2-line, 16-character LCD screen used for display the output, PS/2 mouse or keyboard port can be connected to the FPGA, VGA display port These switches are locked into FPGA using user constraint file (UCF). Figure 6 shows the flow of inputs given to FPGA device. Four slide switches and four push-button switches are used to give the inputs to the FPGA board. They can also act as the reset switches for the various program Kit also has four-output, SPI-based on board Digital-to-Analog Converter (DAC) on board which is to be interfaced to give the analog output to the digital data values. Two-input, SPI-based [7] [23] Analog-to-Digital Converter (ADC) with programmable gain preamplifier converts the real world analog signals into digital values.' Image processing inputs are given by the switches of kit and functionally tested on the corresponding LED's output.T he output data is flashed on LEDs. These LEDs are also locked in UCF file [16]. The bit file of the program is burn out in The EPROM of FPGA and corresponding result is shown by blinking LEDs. The output can be shown on Digital storage oscilloscope (DSO). As shown in figure 7. The input data is 10101010, when reset switch = 0, no output is display on DSO. When reset switch =1, output data is 10101010.

![Figure 1 : Two dimensional (2D) cross point topological (8 8) structure[12]](https://computerresearch.org/index.php/computer/article/download/100750/version/100750/1-Synthesis-Approach-of-D-Mesh_html/12567/image-3.png)

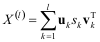
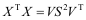
![[21] used to display various encoded data on screen. The Sparten 3E kit is shown in the figure 5. Switches are the input for clk, reset, row_addressn[2:0], column_address [2:0] , network_address [1:0]. Eight bits data data_in[7:0] is also given using switches.](https://computerresearch.org/index.php/computer/article/download/100750/version/100750/1-Synthesis-Approach-of-D-Mesh_html/12572/image-8.png)
![Figure 6 : Sparten-3 FPGA view [21]](https://computerresearch.org/index.php/computer/article/download/100750/version/100750/1-Synthesis-Approach-of-D-Mesh_html/12573/image-9.png)
| Row | Column Address | |||||||
| Address | 000 | 001 | 010 | 011 | 100 | 101 | 110 | 111 |
| 000 | n 1 | N 2 | N 3 | N 4 | N 5 | N 6 | N 7 | N 8 |
| 001 | N 9 | N 10 | N 11 | N 12 | N 13 | N 14 | N 15 | N 16 |
| 010 | N 17 | N 18 | N 19 | N 20 | N 21 | N 22 | N 23 | N 24 |
| 011 | N 25 | N 26 | N 27 | N 28 | N 29 | N 30 | N 31 | N 32 |
| 100 | N 33 | N 34 | N 35 | N 36 | N 37 | N 38 | N 39 | N 40 |
| 101 | N 41 | N 42 | N 43 | N 44 | N 45 | N 46 | N 47 | N 48 |
| 110 | N 49 | N 50 | N 51 | N 52 | N 53 | N 54 | N 55 | N 56 |
| 111 | N 57 | N 58 | N 59 | N 60 | N 61 | N 62 | N 63 | N 64 |
| Network_Address | Selection Logic |
| 00 | Network 1 is selected |
| 01 | Network 2 is selected |
| 10 | Network 3 is selected |
| 11 | Network 4 is selected |
| III. Result & Performance Evaluation | |
| and 6 |
| Logic Utilization | Used Available Utilization | ||||
| Number of Slices | 335 | 2448 | 13 % | ||
| Number of Slice Flip Flops | 80 | 4896 | 1 % | ||
| Number of 4 input LUTs | 653 | 4896 | 13 % | ||
| Number of bonded IOBs | 31 | 158 | 19 % | ||
| Number of GCLKs | 2 | 24 | 8 % | ||
| a) Timing Summary for 8 x 8 NOC | |||||
| Timing details provides the information of delay, | |||||
| minimum period, minimum input arrival time before | |||||
| clock and maximum output required time after clock [1]. | |||||
| Speed Grade: -5 | |||||
| Minimum Period : 4.937 ns (Maximum Frequency: | |||||
| 202.536 MHz). | |||||
| VI. | Conclusion | ||||
| The | hardware | chip | for | 2D-2D | |
| intercommunication network is | |||||