1. I. Introduction
obile learning (ML) emerged as an essential and successful learning method due to its flexibility of time and place for learning in the present globe. On the other hand, learners and teachers have an interactive and cost-effective learning environment for carrying out educational activities with cutting-edge technology advancements. However, at the same time, learners and teachers experience various limitations in this learning method, such as the quality of the learning applications. Therefore, it is vital to evaluate ML applications in various dimensions, such as their ML applicability [1]. The Cambridge Oxford Dictionary defines applicability as "the fact of affecting or relating to a person or thing." Applicability definitions for domains related to computer systems are minimal. Hence we found a specific definition for the public health sector domain, and it defines applicability as "the extent to which an intervention process could be implemented in another" [2]. On the other hand, transferability gives a meaning similar to applicability. It defines transferability as "the extent to which the measured effectiveness of an applicable intervention could be achieved in another setting". Rosemann and Vessey (2008) proposed the significance and capability to check the applicability of a research framework with three factors, i.e., importance, accessibility, and suitability [3]. Accordingly, we can recognize an applicable mobile learning system (MLS) as "the extent to which a MLS could be implemented effectively in a target environment as well as in another environment with a similar setting". This study's main objective is to evaluate the applicability of the proposed mobile learning framework (MLF). This framework consists of seven independent variables, and each variable has different influencing factors. Evaluating this MLF for applicability would help realize the proposed framework's applicability when it works in a real-world environment. Normally, pattern mining algorithms are used to describe patterns in usage behaviors [4]. Hence, we use pattern mining to study users' usage of different learning tools in the system, such as chat, forum, quizzes, assignments, etc. Proper understanding of these usages would help calculate how many users apply these tools in their academic activities in the proposed system. Considering each tool's usage would support predicting the system's overall applicability (Fig. 3: motivating example). Because if a learning system has better applicability, its users should fully practice the tools integrated into it. In this study, the authors intend to analyze the transactional log of the MLS, developed using the proposed MLF for evaluating applicability. According to the previous studies, the FP-Growth [5] efficient pattern mining and Apriori [6] popular association rule mining algorithms have been utilized to evaluate many automated systems. FP-Growth algorithm was used to evaluate systems to identify important segments in learning materials [7], learning behaviors [8], best course modules [9], learners requirements [10], offensive activities, and illegal transactions [11]. In these studies, the FP-Growth algorithm helps to improve the learning process, course selection [9], course recommendation [10], security enhancement, and legal judgments [11] in learning systems and portals. On the other hand, the Apriori algorithm was used to evaluate systems to identify, information for decision making [12], tourists attractive places [13], course administration history [9], study preferences, archived cyber-attacks, and network hackings [14], requirements in software [15], health clinical information in clinical [16], and deformation states of landslides [17]. In these studies, the Apriori algorithm help in different activities such as better administrative decisions [12], improving tourist attraction [13], enhancing course facilities, offering productive subjects [9], preventing networks attacks [14], recommend software requirements [15], enhanced health decision and treatments [16], and predict landslides accurately [17]. But it is a very shortage of using FP Growth or Apriori algorithms in the evaluation applicability of learning systems. Also, difficult to find such applicability evaluation using any statistical approach too in previous studies. Moreover, these two well-established algorithms have no direct provisions for evaluating the applicability of the system. Nevertheless, using the rules and frequent patterns generated by Apriori and FP Growth algorithms can predict applicability. In this study, the authors proposed a novel frequent pattern mining algorithm for applicability evaluation directly in the proposed learning system to address this research gap. Also, FP Growth and Apriori algorithm are used to predict the applicability of the same system.
2. II. Related Work
Pattern mining is a popular data mining tactic to emerge secret knowledge in data stores, and it is applied for solving issues arising in various scenarios. A Pattern mining approach was proposed to identify the most critical or complex learning segments in video tutorials. The proposed method integrates a learning model that learns the above-considered components of the analysed video transaction log. [7]. A pattern mining framework was proposed to identify learners' different learning behaviors and improve their learning process with the institutional learning system. This study's output reveals that the learners obtained significant study performance in different learning modes via various tools integrated into the system [8]. Another pattern mining framework was proposed to analyse huge databases by addressing existing pattern mining algorithms such as a large number of searching iterations, excessive space for processing, and too much time requirements. Results reveal that this approach can solve different kinds of pattern mining problems [18]. An online course recommender system was proposed using the FP-Growth algorithm to guide learners to select learning courses according to their preferences. The investigation displays that the system has better efficiency in instructing learners for selecting appropriate learning materials in their learning process [9]. FP-Growth-based data mining technique was used to promote educational services in educational institutes. Various variables related to learners and educational institutes were employed on FP-Tree to determine regular data items. Research reveals that the best selection of attributes in the data for the algorithm gives better results [19]. FP-Growth algorithm was used to elaborate users' access patterns in learning portals. The study revealed, such as learners' favorite courses, less and high navigation areas of the learning site, and recommendations for advancing both learner's gain and user-friendliness of the site [10]. Wu and Zhang (2019) researched to extract support information to prove offensive actions. An improved FP-Growth algorithm analysed data associated with illegal transactions and supported legal judgment with better efficiency and accuracy [11].
Another method for hidden information recovery from large databases is associate rule mining, and its applications are spread in various researches in the past. The E-learning system was evaluated by combining the association rule mining method and the fuzzy analytic hierarchy process [20]. Apriori algorithmbased association rule mining was used to analyse the Wi-Fi data in attractive tourist places. The study results give the association rules of travel patterns of tourists' movements and enable further enhancements of tourist's magnetism of travel destinations [13]. Learner assisting study guides approval mechanism was proposed using association rule mining with archived course administration data. This approach queries useful relationships in learners' learning subject preferences [9]. An improved Apriori algorithm is offered to find fresh network attacks using the data that was produced by previous episodes. This method has optimal accuracy with superior efficiency for discovering cyber strikes [14]. A customized Apriori algorithm was used to improve the audit system's security building association rules using fewer scanning cycles in logs with shorter processing time [21]. Apriori algorithmbased recommender system was proposed to enhance the accuracy of requirements in software development [15]. Apriori algorithm was coustomized to excavate intelligence information from virtual reality applications for effective decision making [22]. Apriori algorithm was executed successfully in analyzing the deformation states of landslides [17]. A heart disease prediction model was proposed by applying the Apriori algorithm in clinical datasets [23]. Here, we used the Apriori associate rule mining and FP-Growth frequent pattern mining algorithm-based approaches as comparable methods to the novel proposed pattern mining algorithm for evaluation applicability of the proposed MLS.
3. III. Preliminaries
In this section, the authors discuss the proposed MLF and its implemented MLS, which will be evaluated for applicability. Also, the critical theories undergo related to the proposed solution for evaluating the system's applicability, such as associate rule mining, Apriori, and FP-Growth algorithms.
4. a) Mobile Learning Framework for Higher Education
We can refer to many frameworks that were implemented in the Moodle environment successfully in previous studies. Halvoník and Kapusta (2020) implemented an e-Learning material composing framework through Moodle LMS with the teachers' highest inclination [24]. A framework for evaluating student learning was performed through the Moodle platform to create useful tests for learners [25]. Karagiannis and Satratzemi (2017) proposed a Moodle implemented framework for e-learning content adaptation according to learner wishes and better usability with decent learning outcomes [26]. Hence, according to the literature, several conceptual frameworks have been implemented via the Moodle mobile learning environment (MMLE). So in our study, we implemented the proposed conceptual MLFrame through the MMLE.
In this study, we require to measure the applicability of the MLS implemented based on the proposed MLF for higher education (MLFrame). This framework consists of seven independent variables: learner, teacher, mobile ML devices, ML tools, ML contents, higher education institutes, and communication technology (Fig. 1). Each independent variable has several influencing factors: motivation, usefulness, interactivity, ease of use, etc. These factors were realized through various resources and facilities embedded in the MLS such as chat, forum, games, quizzes, assignments, etc. [27], [28]. This MLFrame was implemented in the MMLE by integrating new facilities and modifying the existing Moodle mobile application. Therefore, existing Moodle plugins were enhanced to develop these new ML facilities for the Moodle mobile environment [28]. Because most of the facilities available in the Moodle learning environment are not implemented in the Moodle mobile environment. Hence, when implementing the MLFrame in the Moodle mobile environment, we customized the Moodle ML application by upgrading relevant plugins to serve the facilities introduced in the MLFrame. 3 depicts the concept associated with predicting the system applicability. Consider a MLS with facilities chatting, forum, quiz, assignment, book, video, game, and app_usage. If this app was allowed to use 100 particular users, then assume transaction log analysis as follows. 8,7,6,5 features out of all 8 features used by 60,10,15,5 users, respectively. Therefore, 70 users out of 100 users used at least 7 features out of all 8 features (or 88% features). Hence system applicability was 70% for 88% feature usage. Further, 85 users out of 100 users used at least 6 features out of 8 features (or 75% features). Hence system applicability is 85% for 75% features usage. Similarly, it can be realized that the system applicability is 90% for 63% features usage.
5. Fig. 3: Example for Predicting Applicability using Pattern Mining Algorithm c) Associate Rule Mining
Association rule mining is used to find essential associations among stored data in large databases. 'Antecedent' and 'Consequent' are significant two fractions in association rules. These are data items finding in databases, and 'Antecedent' combines with the 'Consequent'. Moreover, finding frequent itemsets is a crucial requirement to mine association rules from databases. Additionally, two important factors, such as support and confidence, must be defined when finding association rules using these frequent itemsets [29].
6. d) Apriori Algorithm
Apriori is a Latin term which denotes "from what comes before". Bottom-up and breadth-first search strategies are taken into account. Agarwal and Srikant (1994) developed the Apriori algorithm for generating associate rules by frequent pattern mining. The main terminologies used in the Apriori algorithm are Min_supp, Min_conf, Frequent itemsets, Apriori Property, Join Operation, Join Step, and Prune Step [30].
7. e) Frequent Pattern (FP) Growth Algorithm
FP-Growth is a widespread pattern mining algorithm used in data mining. In this algorithm, frequent patterns are stored in a tree-like data structure called FP-tree. The algorithm's main steps are calculating each database item's support count by scanning, deleting irregular patterns, and order remains. Then FP-tree is constructed and frequent patterns are generated using FP-tree [5]. This improves the frequent pattern mining technique because it scans the database only twice. There is no candidate set generation, though it is not suitable for mining patterns in databases that are updated frequently [31].
© 2023 Global Journals
8. a) Process of the Proposed Algorithm
The processing steps of the proposed algorithm implementation are described below.
Procedure 1: Purpose is generating a features list (extracting unique features, used in this evaluation, stored in the transaction log of the system)
Step 01 & 09: For loop iterates from 1 st row to last row of the transactional database.
Step 02 & 08: For loop iterates from 1 st item to the last item of a transactional database row.
Step 03 & 07: For loop iterates from 1 st item to the last item of the array call Array Features. Array Features is an array that contains unique features of the transactional database.
Step 04: Check whether each item does not exist in the array Array Features (f m ).
Step 05: If the new item is not in the array, the item is saved in Array Features as the last item (f s+1 Step 14: Check each item in the transaction database (a ij ) with feature items in Array Features (f m )
Step 15: If a similar item is found, replace the value in the Array Dataset BIMF with 1. The position of the item (i.e. d im ) substituting in the Array Dataset BIMF is found by taking the associate item's row number of the transactional database (i th row ) and column number of the Array Features (m th column).
Likewise, replace 0 with 1 in Array Dataset BIMF to denote similar features in the same column in Array Dataset BIMF for all items in the transactional database. The second last element (n+1) of each row of the array is the Total Decimal Value of binary digit positions in entire Transactions (tdvt i ).
tdvt i =? ?? ???? ??-1 ?? =02 ?? ; where d ij is the digit value of j th position in i th transaction i.e., d ij ={0,1}
The last element (n+2) of each row of the array is the Count of the Non-zero Binary digits in each transaction row (cnb i ).
cnb i = ? ?? ???? ??-1 ?? =0; where d ij is the digit value of j th position in i th transaction i.e., d ij ={0,1}
Step 26: At the end of each row, check whether the percentage of features used in a transaction is greater than or equal to minFUT. The minFUT is the given threshold value for the percentage of minimum features usage in a transaction. For instance, if minFUT = 70% for a 10 features transaction means, at least 7 features are used out of 10 features by a user.
(If j = n and cnb i (100/n) >= minFUT then)
If the above condition is satisfied, then save the transaction pattern to another array (i.e., ArrayPatterns).
In each row of ArrayPatterns[tdvt k , pattern Count k ], tdvt k denotes total decimal values of binary digit positions in entire transactions. Feature usage transaction patterns can be derived by taking the binary conversion of the tdvt i . And patternCount k gives the count of the number of occurrences of the pattern.
Step 27: For loop iterates from 1 st row to last row of the ArrayPatterns[] Step 39: Percentage of each distinct usage transaction pattern can be calculated by using the equation, Percentage of k th pattern = (patternCount k /t) * 100
Step 41: Finally, the overall percentage of transactions whose FUT is greater than or equal to minFUT can becalculated by taking the percentage of summation of the element ArrayPatterns[patternCount k ]. i.e. (22) For j = 1 to s+2 (s = no of columns in ArrayDatasetBIMF[]) (23) insert item d ij to ArrayTDVT[] on the position i th row and j th column (24) Next j (25) Insert tdvt i =? ?? ???? ð??"ð??" ??=?? ?? (??-??) , cnb i = ? ?? ???? ð??"ð??" ??=??
to ArrayTDVT as columns s+1 and s+2 in the i th row (26) If j = s and cnb i *(100/s) >= minFUT then (27) For k = 1 to no of rows in ArrayPatterns (28) Read
9. b) Algorithm Implementation with a Sample
Fig. 4 depicts the generation of the required dataset by implementing the proposed algorithm to evaluate the applicability of MLFrame. In this example, five features were considered for the transaction database. Moodle tools usage and users tables of the log database of the system were used to create the transaction dataset.
Step 01: 'Transaction' table is created by copying user ids from the main user table and updating each user id from the tools usage log table in the database of the MLS.
Step 02: 'ArrayFeatures' table is created by inserting distinct features in the 'Transaction' table. As we use only 5 features, this ArrayFeature table consists of a row with five values.
Step 03: 'ArrayDatasetBIMF' consists 5 rows (transactions of 5 users) and 6 columns (the first column is for TID-transaction ids and the rest of the rows for features). The array consists of user ids and 5 tools (features) same order with the 'ArrayFeatures' in a particular row.
Step 04: The table 'ArrayTDVT' is created by adding two columns at the end to the 'ArrayDatasetBIMF'. New columns are 'TDVT,' and 'CNB' represents the decimal value of the binary values in the same row and the count of non-zero binary digits in the same column, respectively.
Step 05: Different feature usage patterns with frequency are stored in the array called 'ArrayPatterns'. Unique feature usage patterns are selected by satisfying the condition, each pattern's minimum number of features are greater than or equal to the minimum feature usage percentage (minFUT) supplied. Existing Pattern Mining Algorithms Popular algorithms for pattern mining such as Apriori and FP-Growth generate itemsets or candidate itemsets to find frequent itemsets. These itemsets are a group of transactional items that reside in the transaction database. Then, they use a minimum threshold value to minimize or prune itemsets to reduce data considered in mining. On the contrary, the BTPM algorithm uses an entirely mathematical technique, i.e., binary incidence matrix format of the transactional database with mathematical calculations. This reason minimizes memory usage and time for searching or traversals. Furthermore, in this method, the minimum
10. V. Methodology
The proposed MLS was given to precisely 1000 users, who are learners and teachers in the University of Kelaniya's four faculties. Among them, 220 students from each faculty of Science and Commerce & Management, and 200 students from each Faculties of Social Sciences and Humanities. Also, 160 teachers participated, and they consisted of 40 teachers in each faculty mentioned above. They were asked to use the system for around 50 days. This study was conducted according to the research framework illustrated in Fig. 5. The standard log file was extracted, and approximately half a million records were identified as different transactions related to the above user group on the given spell. Transactions were categorized into eight transactions with facilities integrated into the proposed ML application, i.e., chat, forum, quiz, assignment, book, video, game, and app_usage. The app_usage represents general user activities associated with the mobile application, such as page viewing, information modifying and deleting, etc. These activities were classified according to each user (Table 4). Finally, the transaction dataset was generated using the above eight features for all 1000 users. This dataset completed preprocessing steps to be perfect for applying algorithms such as filling in missing data and removing unusual data. This dataset consists of 1000 records, and each record represents different transactions done using the proposed ML app.
The proposed data mining-based novel frequently pattern mining algorithm was primarily implemented using Python programming language to describe the proposed MLS's applicability (Table 1: BTPM Algorithm), and it was applied to the dataset. This algorithm caters to finding patterns of feature usage in transactions and calculating percentages of each different transaction pattern. For instance, what is the percentage of different patterns including all the features considered above (i.e., chat, forum, quiz, assignment, book, video, game, and app_usage), or what are the percentages of different patterns including seven features out of the eight features considered above? Then overall applicability of the system can be predicted by considering these transaction patterns and taking the summation of their percentage values. Next, the Apriori algorithm for associate rule mining and the FP-Growth algorithm for frequent pattern mining were applied on the same dataset and generated the best possible rules which can describe the overall systems' applicability.
Finally, the proposed BTPM algorithm's performance was compared with Apriori and FP-Growth algorithms. For that, a data set with 15000 records were used. The dataset was created by using the original data set multiple times with changing the order of records randomly. Each algorithm's execution times were recorded by changing number of execution records (i.e. 2500, 5000, 7500, 10000, 12500, 15000) and percentage of minimum feature usage (supports) (20%, 40%, 60%, 80%).
11. C
Various activities in the MLS are used as eight features in the transaction dataset. Feature descriptions are mentioned in Table 2.
12. VI. Results and Discussions a) Dataset
In this study, we use a data set including 1000 transactional rows of 1000 users. Each transaction row consists of 8 features denoting activity usage in the MLS. The second subprocedure in the proposed algorithm converts the transactional dataset to the BIMF dataset, and part of the BIMF dataset is shown below (Table 3).
13. C
The proposed algorithm gives 16 different patterns of features used in transaction rows. We considered 75% as the minimum threshold value for minimum feature usage in a transaction (6 features out of 8 features) (Table 4). Thus, we ask the proposed algorithm to give different patterns in the dataset, consisting of at least six features out of the eight total features in a single transaction. Results reveal that 43%, 24%, 15% of transactions have used 8, 7,and 6 features consecutively. Therefore 82% of transactions have used at least six features(75% of features). Hence, we can predict that the system's applicability is 82% when the minimum threshold feature usage in a transaction is 75%. Year 2023 The authors use values 40%, 40%, and 1.0 for Apriori parameters, i.e., support, confidence, and lift, respectively to build the Apriori model Using these parameters 267 rules were generated. We chose these values to get 8-itemset combinations. Therefore, according to the 15th rule mentioned in table 05, support, confidence, and lift of 8-itemset are matched with the above minimum parameter values. Otherwise, we were unable to obtain 8-itemset combinations. Fifteen specific rules were selected whose antecedent is the app_used feature. Since all the users use the app_used feature, the support of the app_used feature is 100%. Therefore, we can assume that the maximum feature usage in transactions comes for an itemset whose antecedent is App_usage. According to the Apriori algorithm results (Table 5), rule 15 reveals that its confidence is 43. Rule 15 denotes that 43% of users use the app with seven other features. This indicates that 43% of users used all the considered features in the proposed system. Hence, both the proposed novel algorithm and the Apriori algorithm gave the same output percentage value for eight feature usage in transactions. Similarly, according to the confidence value of rule 14 and rule 13, we can assume that the maximum percentage for the usage of 7 features in transactions is 51%, and the maximum percentage for six features usage in transactions is 61%. Finally, using the Apriori algorithm results, we can assume that the proposed system's overall applicability should be greater than 61% when at least 6 features are used in a transaction.
14. d) Results of the FP-Growth algorithm
FP-Growth algorithm gives the following patterns as frequent patterns for the above dataset with 40% as both minimum threshold values for support and confidence parameters. These results denote that 40% of users use at least seven features among the eight features. Also, 60% of users use at least six features among the eight features. These results secure the 75% usage of the features by 60% of users. Therefore, we can assume that the applicability of the system is not less than 60% when minimum feature usage in a transaction is equal to 75% for the FP-Growth algorithm.
15. e) Evaluating the Algorithm
The performance of the proposed algorithm for pattern mining was compared with Apriori and FP-Growth algorithms. The results clearly show the better efficiency of the proposed algorithm. According to the graphs in Fig. 6, the proposed algorithm (BTPM) takes less execution time than the Apriori and FP-Growth algorithm for different support thresholds in each size of transactions. Reasons for these performances in the proposed algorithm are, it scans the database only once to develop an array of features. Also, the BIMF dataset and mathematical process have quicker processing power in the proposed algorithm. On the contrary, other algorithms considered in this study use techniques to mine frequent patterns such as scans database iteratively, creating candidate itemsets, and a frequent pattern tree. However, if our proposed algorithm uses the BIMF dataset directly, these execution times reduce further.
16. Global
17. f) Time complexity of the proposed algorithm
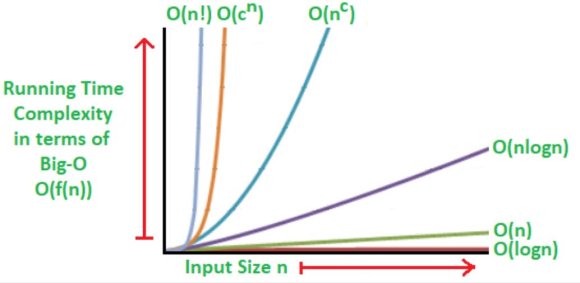
The time complexity of an algorithm is the time estimation to execute the programming code inside the algorithm. It depends on the building blocks or control structures used in the algorithm, such as sequence, selections, and iterations. Further, the situation differs when the input is increasing. According to table 8, the total time complexity is equal to the summation of time complexity of procedure 1, procedure 2, procedure 3, and procedure 4. It is close to O(N 2 ).
Therefore the time complexity of the proposed BTPM algorithm is realized approximately as O(N 2 ). According to the previous studies, the Apriori algorithm's time complexity was calculated as O(N 2 ) for a larger dataset [33]. But Tahyudin and colleagues (2019) show the time complexity of the Apriori algorithm as O(2 N ) [34]. Also, the FP-Growth algorithm's time complexity is O(N log N) for higher data volumes, while in lower datasets, it shows O(N) better performance [35]. According to Fig. 7, the proposed BTPM algorithm's time complexity has similar or a little better to the Apriori algorithm for more extensive data volumes. The purpose of creating the BTPM algorithm is to evaluate the proposed algorithm for applicability. BTPM algorithm provides the applicability of the MLS directly. But when Apriori and FP Growth algorithms are used to evaluate applicability, it requires certain assumptions, as mentioned in 6.3 and 6.4.
18. VII. Conclusion and Implication
This study's primary purpose is to check whether the proposed MLF for higher education is applicable for higher education learners and teachers. The framework was implemented via a modified MMLE. This study was carried out using generated MySQL standard system log files integrated with a Moodle learning management system. In this study, the authors


![Purposes are, 1) Saving BIMF dataset (ArrayDatasetBIMF[]) to an Array (ArrayTDVT[]) by creating tdvt and cnb. (tdvt: Total Decimal Value of binary digit positions in entire Transactions; cnb: Count of the Non-zero Binary digits) 2) Selecting and Saving Patterns to ArrayPatterns Step 20: Create arrays named ArrayTDVT[] and ArrayPatterns[] Step 21: For loop iterates from 1 st row to last row of the ArrayDatasetBIMF[] Step 22: For loop iterate from 1 st column to last column+2 ArrayDatasetBIMF[] Step 23: Insert items (features) in Array DatasetBIMF[] to ArrayTDVT[] by row wise. Step 24: Advance the inner loop Step 25: Once particular row of Array DatasetBIMF[] is inserted to ArrayTDVT[], tdvt and cnb values are insertedto the same row in ArryTDVT[] as last tow column.](https://computerresearch.org/index.php/computer/article/download/102325/version/102325/1-A-Novel-Frequent-Pattern_html/41576/image-4.png)
![Read existing tdvt values in the ArrayPatterns[] Step 30: If the existing tdvt value equals the tdvt value, satisfy the conditions in Step 26, increase the patternCountvalues in the ArrayPatterns by one ArrayPatterns[tdvt k , patternCount k = patternCount k + 1] Step 32: If the existing tdvt value does not equal the tdvt value, satisfy the conditions in Step 26, add new row tothe ArrayPatterns ArrayPatterns[tdvt k+1 = tdvt i , patternCount k = 1] Purposes are generating patterns and their percentages Step 37: For loop iterates from 1st row to last row of the ArrayPatterns[] Generate distinct transaction patterns by converting tdvt k to its binary pattern whose percentage of featureusage in a transaction is greater than or equal to minFUT. k th Pattern = CtoBinary(tdvt k ) k th pattern can be realize by considering both CtoBinary(tdvt k ) and the ArrayFeatures[]. CtoBinary(tdvt k ) and the ArrayFeatures[] array have same no of elements. We can identify the pattern by replacing non-zero digits in CtoBinary(tdvt k ) with the element in the same position of the ArrayFeatures[] and ignoring zeros.](https://computerresearch.org/index.php/computer/article/download/102325/version/102325/1-A-Novel-Frequent-Pattern_html/41577/image-5.png)


| Array Features consists of an array of distinct features in | |
| the transactional database. | |
| Procedure 2: Step 10: Creating an array calls Array Data Set BIMF[] | |
| for saving the transactional database in binary incidence | |
| format array size is: | |
| t x s; t means the number of transactions in the | |
| transactional database;s means the number of features | |
| in the array Features[]. Assign 0 for all the array | |
| elements. | |
| Step 11 & 19: For loop iterates from 1 st row to last row of | |
| the transactional database | |
| Step 12 & 18: For loop iterates from 1 st item to the last | |
| item of a transactional row | |
| Step 13 & 17: For loop iterates from 1st item to the last item of the array called Array Features[]. (Note: Array Features[] contains distinct features of the transactional database) | Volume XXIII Issue II Version I |
| ( ) C | |
| Global Journal of Computer Science and Technology |
| ?? ??=1 | ? × | 1 ?? | × 100 |
| Where L = No. of patterns = Number of rows in the | |||
| ArrayPatterns, t = no. of transactions in the dataset | |||
| Feature | Type | Description |
| ID No. | Identification | Student identification number |
| Chat | Activity | Chat facility for discussions |
| Forum | Activity | Forum facility for knowledge sharing |
| Quiz | Activity | Quiz facility to test learners' knowledge |
| Assignment | Activity | Assignment for extra academic tasks |
| Book | Activity | Book-facility for further reading |
| Video | Activity | Video facility for academic activities |
| Game | Activity | Game facility for academic activities |
| App_usage | Activities (View/Modify/..) | General activities in the mobile app such as view, modify.. |
| PNo | F1 | F2 | Features (F 1 to 8 ) F3 F4 F5 | F6 | F7 | F8 | No. of Features used | Each rule percentage (%) | Each rule group percentage (%) | FUT Percentage (%) | |
| 1 | App used | Assign ment | Book Chat Forum Quiz Video Game | 8 | 43 | 43 | |||||
| 2 | App used | Assign ment | Book Chat Forum Quiz Video Null | 7 | 2 | ||||||
| 3 4 | App used App used | Assign ment Assign ment | Book Chat Forum Quiz Null Game Book Chat Forum Null Video Game | 7 7 | 1 6 | Year 2023 | |||||
| 5 | App used | Assign ment | Book Chat | Null | Quiz Video Game | 7 | 2 | 24 | 11 | ||
| 6 | App used | Assign ment | Book Null Forum Quiz Video Game | 7 | 2 | 82 | |||||
| 7 | App used | Assign ment | Null Chat Forum Quiz Video Game | 7 | 3 | ||||||
| 8 | App used | Null | Book Chat Forum Quiz Video Game | 7 | 8 | ||||||
| 9 | App used | Null | Book Chat Forum Null Video Game | 6 | 4 | ||||||
| 10 | App used | Null | Book Chat Forum Quiz Null Game | 6 | 1 | 15 | |||||
| 11 | App used | Null | Null Chat Forum Quiz Video Game | 6 | 3 | ||||||
| 12 | App used | Assign ment | Null Chat | Null | Quiz Video Game | 6 | 1 | ||||
| Volume XXIII Issue II Version I | |||||
| ( ) | |||||
| Global Journal of Computer Science and Technology | |||||
| Rule No. Antecedent | Consequent | Support (%) | Confidence (%) | Lift | |
| 1 | App_used | Assignment | 71 | 71 | 1.0 |
| 2 | App_used | Quiz | 72 | 72 | 1.0 |
| 3 | App_used | Forum | 92 | 92 | 1.0 |
| 4 | App_used | Game | 85 | 85 | 1.0 |
| 5 | App_used | Book, Forum | 73 | 73 | 1.0 |
| 6 | App_used | Game, Chat | 82 | 82 | 1.0 |
| 7 | App_used | Chat, Video | 82 | 82 | 1.0 |
| 8 | App_used | Forum, Chat, Video | 79 | 79 | 1.0 |
| 9 | App_used | Game, Chat, Video | 74 | 74 | 1.0 |
| 10 | App_used | Game, Chat, Forum | 76 | 76 | 1.0 |
| 11 | App_used | Game, Forum, Video | 73 | 73 | 1.0 |
| 12 | App_used | Video, Game, Chat, Forum | 71 | 71 | 1.0 |
| 13 | App_used | Video, Game, Book, Chat, Forum | 61 | 61 | 1.0 |
| 14 | App_used | Video, Game, Forum, Quiz, Chat, Book | 51 | 51 | 1.0 |
| 15 | App_used | Game, Assignment, Book, Forum, Chat, Quiz, Video | 43 | 43 | 1.0 |
| Pattern description | Min. support | Min. confidence | Number of patterns |
| 7-itemset (7 feature items patterns) | 40% | 40% | 8 |
| 6-itemset (6 feature items patterns) | 40% | 40% | 28 |
| 6-itemset (6 feature items patterns) | 50% | 40% | 28 |
| 6-itemset (6 feature items patterns) | 60% | 40% | 8 |
| Exec. | 20% Support | 40% Support | 60% Support | 80% Support | ||||||||
| Records | Apri | FP | BTPM | Apri | FP BTPM Apri | FP BTPM Apri | FP BTPM | |||||
| 2500 | 387 | 195 | 161 | 141 | 121 | 110 | 118 | 113 | 101 | 117 | 103 | 92 |
| 5000 | 961 | 202 | 189 | 617 | 176 | 171 | 450 | 161 | 155 | 345 | 148 | 137 |
| 7500 | 1969 1255 | 349 | 1417 | 899 | 320 | 1117 | 750 | 305 | 917 | 559 | 291 | |
| 10000 | 2946 1846 | 431 | 2014 | 1532 | 420 | 1403 1316 | 413 | 994 | 869 | 407 | ||
| 12500 | 3255 1850 | 454 | 2314 | 1714 | 445 | 1706 1505 | 431 | 1393 | 1110 | 410 | ||
| 15000 | 3779 2107 | 618 | 3513 | 1849 | 600 | 2889 1556 | 574 | 2419 | 1399 | 564 | ||
| Component | Description | Complexity |
| Three nested iterations and an inner if statement with an | O(N*N*M+1+1), M is very close to 1 | |
| Procedure 1 | assignment statement. But innermost iteration considers | and very low to N |
| a low number of transactions well below N. | ~ O(N 2 ) | |
| Procedure 2 | Array create a statement, three nested iterations, inner if statement, and inner assignment statement. But innermost iteration considers a very low number of transactions well below to N. | O(1+N*N*M+1+1) ~ O(N 2 ) ), M is very close to 1 and very low to N ~ O(N 2 ) |
| O(1+1+(N*(N+1)(1+1+1+M+1+1), | ||
| Procedure 3 | M is very close to 1 and very low to N | |
| ~ O(N 2 ) | ||
| Procedure 4 | two assignment statements within a for loop and one outside assignment statement. |
O(N*(1+1)+1) ~ O(N)