1. Introduction
ig Data or Data Integration is basically related with interoperability of data. Big Data deals with divergent fields such as: 1. Substantial data movement 2. Replication of data 3. Synchrony of data 4. Transmutation of data Geoscience is the application and exploration of Earth's minerals, soil, water and energy resources. The variability in Earth sciences in any area can be shown in both spatial and temporal variations.
2. II.
3. Analysis of Big Data
Prior to 2012 U.S was the largest single contributor to global data.
The emerging markets are showing the largest increases in data growth. In 2012, the amount of information stored worldwide exceeded 2.8 zetabytes. By 2020, the total amount of data stored is expected to be 50 times greater than today. What good is all of this data? Data is raw, unrecognized facts that is in and of itself worthless. Information is potentially valuable concepts based on data.
Knowledge is what we understand based on information. Wisdom is effective use of knowledge in decision making.
4. Literature Review
There are many studies wherein many scientists have studied Big Data by inventing customized tools have been developed using various scripting languages. An overview of such studies is discussed in this section. Azza Abouzeid et al devised a paper entitled "Ha doop DB: An Architectural Hybrid of Map Reduce and DBMS Technologies for Analytical Workloads "This paper elaborates on how Hadoop DB is able to approach the performance of parallel data systems and how Hadoop works in het erogenous environments.
Jerome Boulon et al have discussed about "Chukwa: A large-scale monitoring system" used for monitoring and analysing large distributed systems.
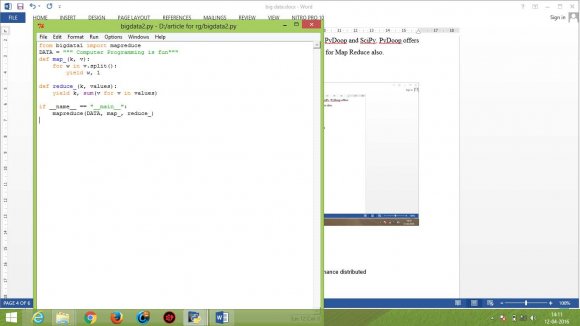
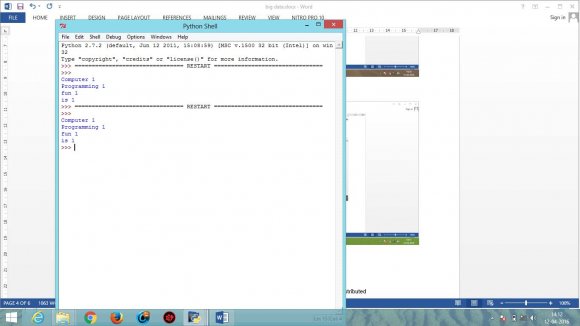
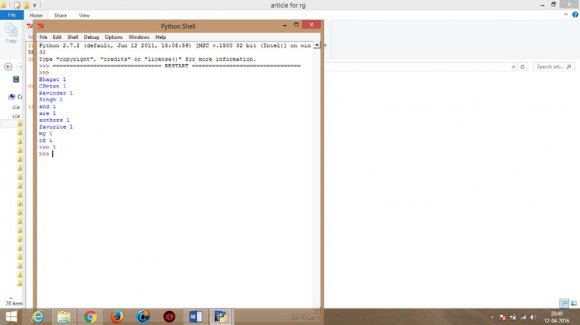
Jeffrey Dean et al have elaborated on "MapReduce: Simplified Data Processing on Large Clusters" which is a programming model and is used processing and generating large data sets. Two functions are used: map function and reduce function.
Tom Narock and Pascal Hitzler discussed about "Crowd sourcing Semantics for Big Data in Geosciences Applications" i.e. how semantic algorithms have been used for achieving accurate data .
Sanjay Ghemawat et al discussed on "The Google File System" which is a scalable distributed file system for large distributed data-intensive applications. It enhances the performance while analysing large clusters of data and provides great performance when dealing with large number of clients. a) Technique used Big Data can be coded in many different languages such as C, C++, Python. However, most suitable language considered for coding is Python. Python is said to be multi-model programming language. It authorize programmers to acquire various methodology of programming: object-oriented and structured programming which is fully sustained by Python. Python offers diverse language characteristics which stimulates functional programming and aspectoriented programming.
There are many factors that favours Python as a language to code for Big Data. In modern times plenty of API's and libraries have been advanced for Python. In research also Python has a lot to implement ranging from networking to GUI development. Thus the interaction among systems has been highly enriched even though it remains a formidable task in many programming languages.
5. Pydoop recommends diverse features which are usually not found in other Python libraries for Hadoop like
MapReduce library which enables users to combine and partition data sets, easily installed library and can be used freely.
SciPy is an open source library that is offered by Python for all the users aiming to do scientific computations. This library furnish various modules such as ODE(Ordinary Differential Equations), FFT(Fast Fourier Transformation),optimization which finds application in the field of science and engineering. The MapReduce provides a framework where large volumes of data can be analysed. The tool can be extended futhur by increasing the volume of data supplied as well as some other scripting language can be adopted by the scientists to enhance the power of Big Data and thus make new discoveries in this discipline. Big Data is emerging as a powerful technique in recent years and provides solutions to the challenges of merging data thus making a mark in manifold fields like banking, health care, education which will involve whole world at large.