1.
Abstract-Web Usage Mining deals with the understanding of user behavior while interacting with the website by using various log files. The whole process of Web Usage Mining gets completed in three phases namely Data Preprocessing, Pattern Discovery and Pattern Analysis. Data Preprocessing is important because it takes 80% of the time of the whole process of Web Usage Mining. Data Preprocessing involves Data Cleaning, User Identification, and Session Identification.
In Session Identification we find out the set of pages visited by a user within the duration of one particular visit to a website, also called as Sessionization.
In paper [1], we proposed a new method for session construction. As the size of log files are very large so there is a requirement of an approach for Session Identification by which processing time of our proposed method will be reduced to a great extent.
In this paper, we used Map-reduce method to calculate sessions in which we combine both time and user navigation method. This approach is faster than the existing approach because we have performed the whole process in distributed environment.
Keywords: web mining, web server logs, web usage mining (WUM), map reduce, session identification.
2. I. Introduction
eb Usage Mining deals with observing user behavior, while interacting with web site, by accessing various log files to extract knowledge from them. This knowledge can be applied for reorganizing the website contents by giving a personalization and recommendation that is more efficient as compared to previous one by improving the links and navigation which in turns increase the rate of advertisement. This will results the users to access the website in a comfortable manner which obviously generate more revenue to them. [2] This scheme comprises of three steps as data preprocessing, data mining and pattern analyzing. Data preprocessing contains three steps as data cleaning, user identification, session identification. Session identification is an crucial step in data processing of web log mining. A session is defined as multiple requests made by a user for a single navigation. A user may have a single or multiple sessions during a particular period. Basically sessions are identified either by Time based method or by Navigation based method.
Author ?: Department of Computer Science, SGSITS Indore (M.P.), India. e-mail: [email protected] Author ?: Department of Information Technology, SGSITS Indore (M.P.), India. e-mail: [email protected] Here, we proposed a unique approach for user session identification by blending Time based method with Navigation based method to get better results.
To increase the pace of Sessionization, the process is performed on distributed systems using Map-reduce. Map-reduce [3] is a programming model and an associated implementation for processing and generating large data sets that supports fault tolerance, automatic parallelization, scalability, and data localitybased optimizations. Users define a Map function that will use this key/value pair for processing the data to generate a set of intermediate key/value pairs and a Reduce function will be called that concatenates all intermediate values related with the same intermediate key.
3. II. Motivation
Map Reduce is a programming model and an associated implementation for processing and generating large data sets. This process takes a set of input key and value pairs and generates an list of key and value pairs. The user of the Map-Reduce library classifies this calculation as two function as map and reduce functions.
The Map function takes a pair of input and generates a list of intermediate key and value pairs. The values grouped with the help of the Map-Reduce library is fed to the Reduce function.
The Reduce function accepts the output that was generated by the library as value and key pair, merge them to produce a small set of values e.g. zero or one value. The intermediate values that were produced during invocation are feded into the Reduce function with the help of an iterator. This will enable the user to handle large set of values so that it will be stored easily in the memory.
4. III. Proposed Approach
In order to enhance the performance of the proposed method in [1], we have used Map-Reduce method to lower the session generation time.
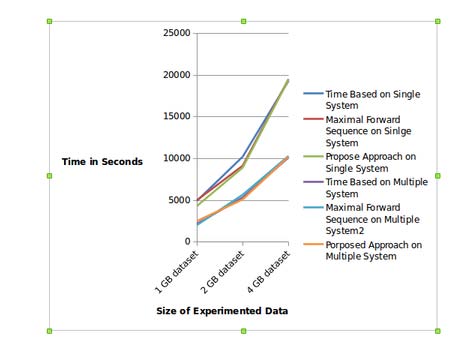
We have applied Map-Reduce on the timebased method, maximal forward sequence method and our proposed method [1]. The results that were generated during this approach has tremendously reduces the session generation time as it was fasten up by the Map and Reduce function.
5. V. Conclusion
The information available on the web is increasing day by day in a fast manner. This lets the user to have a lot of data to access freely on the web. Our method have generated sessions that took less time comparable to the existing method. The experiment on 1GB, 2GB, and 4GB data shows that the new method proposed in [1] generates more sessions (3102) than the traditional Time Based Method (2875) and Maximal Forward Sequence Method (2742). As per the result shown in Table-1 with the proposed approach, this process takes less time in completion because of Map Reduce method.