1. Introduction
veryone uses language to communicate with others, whether it is English, Spanish, sign language, or touch or smell language. Sign language is the language used by deaf-mute people to talk. It varies from country to country and has its own vocabulary. Indian Sign Language (ISL) is a collection of gestures used by the deaf community in India. These gestures are also different in different parts of India.
It is always a challenge for normal people to communicate with deaf-mute people and vice versa. Sign language translation is the solution to this problem. It provides a bridge of communication between the community at large and the deaf-mute community. There are two main methods for the recognition of sign language, glove-based and computer vision-based [1]. In this article, a computer vision-based approach to interpreting ISL in two different ways is discussed. ISL letter recognition includes camera frame extraction, hand masking, feature extraction and classification recognition. This is to identify the alphabet from a single frame. The second method is to recognize gestures through words. The camera frame sequence is used to recognize gestures. It consists of the same modules as letter recognition, but it uses a series of frames instead of one frame. This article focuses on ISL recognition through deep learning and computer vision. The rest of thesis is organized as follows; the second part presents the related work done in gesture recognition. The third part contains the methodology of the two methods of recognition of the Indian sign language. The first method is suitable for static gestures and the second method is suitable for dynamic gestures. Discussion of the results and conclusions are explained in Sections 4 and 5, respectively.
2. II.
3. Related Work
Many techniques have been developed to recognize sign language. There are two main approaches that use tracking sensors or computer vision to track various movements. Much research has been done on sensor-based approaches using gloves and wires [1,2,3]. Therefore, it is inconvenient to wear these devices continuously. Additional work will primarily focus on computer vision-based approaches.
A lot of work has been done using a computer vision based approach. The authors have proposed various methods of recognizing sign language using CNN (Convolution Neural Network), HMM (Hidden Markov Model) and contour lines [4,5,6,7]. Different methods are used to split images such as HSV and color difference images [4,5]. The authors proposed an SVM (Support Vector Machine) method for classification [6,8]. Archana and Gajanan also compared different methods for partitioning and feature extraction [9]. All previous treatises have successfully recognized the ISL alphabet. But in reality, deaf or mute people use speech gestures to convey messages. If the word has a static action, you can use these previous methods to check the word.
ISL Many words required hand movements. The image classification method is not a simple image classification technique, but is suitable for identifying these dynamic gestures. Video-based action recognition has already attracted attention in several studies [10,11,12]. Instead of capturing the color image data for each frame of the video, some researchers performed differences between successive frames and randomly provided these segments to the TSN (Temporal Segment Network) [11]. Sun, Wang and Yeh use LSTM (Long Short-Term Memory) [13] to describe video classification and captions. Juilee, Ankita, Kaustubh and Ruhina used video to suggest a method of hydration recognition in India [14]. As a result of searching the sign language recognition system, most studies use static sign language gestures and video recognition techniques to study dynamic gesture identification and only perform video classification for various actions discovered.
III.
4. Methodology a) Static gesture classification
Experiments were performed on the data set provided by [15]. The dataset contains 36 folders representing 09 and A-Z, each consisting of an image of a hand subdivided by the corresponding alphanumeric skin color. There are 220 images of 110 x 110 pixels each for each alphanumeric character. Figure 1 shows an image of each label in the data set. After training the model, predict the output by performing the following steps:
Frame Extraction: Uses OpenCV library to capture video from webcam for live prediction. After capturing the video, take a single frame and define a region of interest (ROI) in that frame. The area of interest is the area in which a person runs a stream.
5. Skinsegmentation:
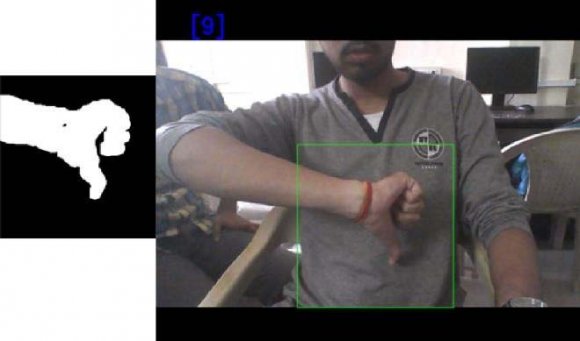
The ROI of the frame is transformed into a hand-masked image to provide to the model for predictive purposes. First, you need to blur the image to reduce noise. This is done by applying Gaussian Blur. After blurring ROI is converted to HSV color scale in RGB. Converting an image to the HSV color scale helps detect better skin than RGB. Next, lower and upper limits are set for skin extraction. Here, (108, 23, 82) was used in the low range and (179, 255, 255) was used in the high range. This range offers us the best results. After selecting a range, compare the values of each pixel and if the value is not within the range, it will be converted to black, otherwise it will be converted to white pixels. This provides us with handmasked images. Still, the hand-masked image is noisy and the edges are not aligned. To solve this problem, use the Dilate and Erode features available in OpenCV to smooth the edges. Prediction: The ROI of the frame is converted to a handmasked image. This hand-masked image is provided as input to the CNN model for prediction. 09 or AZ is provided for the output of the original frame, but it is a predicted value. But this leads to another problem, the frame output keeps blinking. To solve this problem, we used a 25-frame forecast and used the maximum forecast class as the output.
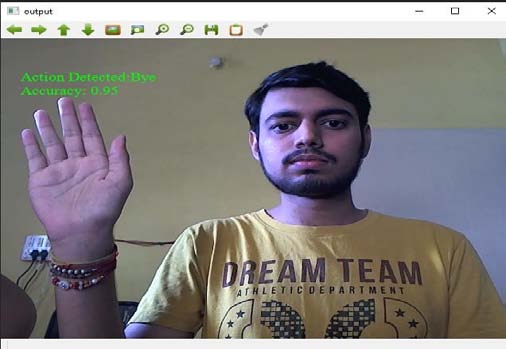
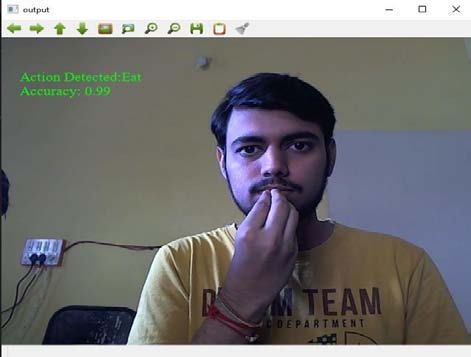
Figure 2 shows a handmasked image of the alphabet L and the final output. Neural networks can help predict complex data and values most of the time. Input is not related to time or is not required in chronological order. This is the case for static gestures in ISL, so a multi-layer CNN architecture is sufficient. However, for dynamic gestures, you cannot perform CNN silver because you have to keep the previous state. Therefore, LSTM networks are useful in this case. LSTM is an RNN (Recurrent Neural Network) type that has a structure similar to a chain of repeating modules that is useful for learning long-term dependencies from sequential data. 3. The input continuously delivers a sequence of 8 frames/images extracted from images in the training dataset. Apply an RGB difference filter before serving these 8 frames as input. The RGB difference subtracts the current frame from the previous frame. Therefore, only the changed pixels remain in the frame and the remaining still images are deleted. In this way, it helps to capture time-varying visual features. Here in our case it helps to capture the gesture pattern and the background is also removed so it becomes independent in a variety of background scenarios.
If so, these frame sizes change to 224 x 224 pixels. This is because the next layer is a MobileNetV2 layer that only accepts image sizes up to 224 x 224 pixels. As a pre-trained model, we used the weight of `Imagenet` and MobileNetV2. MobileNetV2 can be used as a pre-trained model used for image segmentation, eliminating the task of building CNN models for image segmentation. Separate the Mobile Net V2 layer for passing these 8 frames with Time Distributed layer used. Here I use the Time Distributed Global Average Pooling layer as I need to flatten the frames to insert a series of frames into the LSTM. Finally, there is a multi-layer LSTM structure with several dropouts and a fully connected layer to reduce the sum of overcharges. LSTMs help recognize pattern formation with dynamic / moving hand gestures. Finally, SGD is used in optimization programs because it provides better results when the available data set is low. Adam provides good results even when the dataset is large.
IV.
6. Results and Discussion
7. a) Static gesture classification
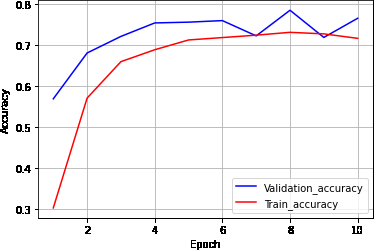
During checking out of the static hand gesture version and figuring out the greatest architecture, 10epoch models were each trained using various optimizations such as RMSProp, SGD, Adam, etc. By the way, RMSProp gave the best results with a precision of 73.6°. A graph of accuracy and time is shown in Figure 4 Skin segmentation is an integral part of a system for predicting static hand gestures. It was concluded that the lower range (108,23,82) and the higher range (179,255,255) would give the best results. Figure 5-6 shows the gestures predicted to be skin segmentation. There are some limitations to using skin segmentation to recognize static hand gestures. Most importantly, you need a skin-free background. Predictions are wrong because the background contains colors in the skin color range and it is difficult to hide the skin. For example, if the background is a shade of yellow that falls within our range, this problem will occur. The second problem is a stream of similar shape. The equal gestures with alphabets and numbers overlap. For example, the alphabet "V" and the number "2" have the same gesture and cannot be properly distinguished by the system. There is also a similar hand movement problem that reduces accuracy. For example, the letters 'M' and 'N' are very similar. Other similar pairs are `FX` and `1I`. Removed static parts of the frame sequence using RGB differences to overcome the background color issue. It also leaves the moving hand in the frame, which helps detect hand gesture patterns. The only problem with this approach is that if the background is moving, the sequence of frames will also have a background, which will affect the prediction accuracy. You can also add more videos to different backgrounds and people's datasets for greater accuracy.
V.
8. Conclusion and Destiny Scope
The Deafmute community is faced with communication challenges every day. This white paper describes two methods for recognizing hand gestures: static gestures and dynamic gestures. For static gesture classification, a CNN model is implemented that classifies the motions alphabetically (AZ) and numerically (09) with a precision of 73. Use hand mask skin subdivision with the model For dynamic gestures, we trained a model using multi-layer LSTM using 12word MobileNetV2 and gave very satisfactory results with an accuracy of 85°. For future work with static gestures, another approach to skin segmentation that does not rely on skin color can be built. For dynamic gestures, you can increase the size of data sets with different backgrounds.

| Property | Value |
| ConvolutionLayer | 3Layers (32,64,128 nodes) |
| ConvolutionLayer(KernelSize) | 3,3, 2 |
| MaxPoolingLayer | 3 Layers-(2, 2) |
| FullyConnected Layer | 128nodes |
| OutputLayer | 36nodes |
| ActivationUsed | Softmax |
| Optimizer | RMSProp |
| Hyperparameters | |
| Learningrate | 0.01 |
| No.ofepochs | 10 |