1. INTRODUCTION
spam filter is a program that is used to detect unsolicited and unwanted email and prevent those messages from getting into user's inbox. A spam filter looks for certain criteria on which it stands decisions. For example, it can be set to look for particular words in the subject line of messages and to exclude these from the user's inbox. This method is not effective, because often it is omitting perfectly legitimate messages and letting actual spam through.
The strategies used to block spam are diverse and includes many promising techniques. Some of the strategies like black list filter, white list /verification filters rule based ranking and naïve bayesian filtering are used to identify the spam.
A BF presents a very attractive option for string matching (Bloom 1970). It is a space efficient randomized data structure that stores a set of signatures efficiently by computing multiple hash functions on each member of the set.
It queries a database of strings to verify for the membership of a particular string. The answer to this query can be a false positive but never be a false negative. The computation time required for performing the query is independent of the number of signatures in the database and the amount of memory required by a BF for each signature is independent of its length (Feng et al 2002). This paper presents a BBF which allocates different false positive rates to different strings depending on the significance of spam words and gives a solution to make the total membership invalidation cost minimum. BBF groups strings into different bins via smoothing by bin means technique. The number of strings to be grouped and false positive rate of each bin is identified through GA which minimizes the total membership invalidation cost. This paper examines different number of bins for given set of strings, their false positive rates and number of strings in every bin to minimize the total membership invalidation cost.
The organization of this paper is as follows. Section 2 deals with the standard BF. Section 3 presents the CS technique. Section 4 reports optimized BBF using ECS. Performance evaluation of CS and ECS for the BBF is discussed in section 5.1
2. II.
3. BLOOM FILTER
Bloom filters (Bloom 1970) are compact data structures for probabilistic representation of a set in order to support membership queries. This compact representation is the payoff for allowing a small rate of false positives in membership queries which might incorrectly recognize an element as member of the set.
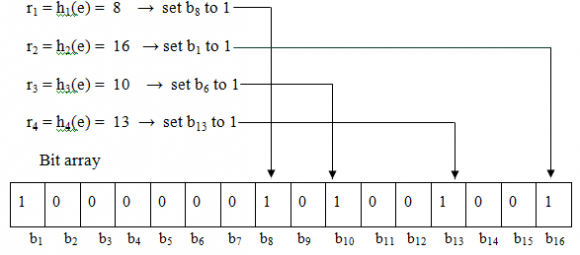
Given a string S the BF computes k hash functions on it producing k hash values and sets k bits in an m-bit long vector at the addresses corresponding to the k hash values. The value of k ranges from 1 to m. The same procedure is repeated for all the members of the set. This process is called programming of the filter. The query process is similar to programming, where a string whose membership is to be verified is input to the filter. The bits in the m-bit long vector at the locations corresponding to the k hash values are looked up. If at least one of these k bits is not found in the set then the string is declared to be a nonmember of the set. If all the bits are found to be set then the string is said to belong to the set with a certain probability. This uncertainty in the membership comes from the fact that those k bits in the m-bit vector can be set by any other n-1 members. Thus finding a bit set does not necessarily imply that it was set by the particular string being queried. However, finding a bit not set certainly implies that the string does
? + ? ? ? ? ? ? ? ? ? =(2)The derivative equals 0 when kmin=(1n2)(m/n). In this case the false positive probability f is:
f(k min ) = (1 ? p) k min = ( 1 2 ) k min = (0.6185) m /n (3) of course k should be an integer, so k is ?ln 2 . (m n) ? ?The BF has been widely used in many database applications (Mullin 1990 (Fan et al,2000). BFs have great potential for representing a set in main memory (Peter and Panagiotis, 2004) in stand-alone applications. BFs have been used to provide a probabilistic approach for explicit state model checking of finite-state transition systems (Peter and Panagiotis, 2004). It is used to summarize the contents of stream data in memory (Jin et al,2004;Deng and Rafiei,2006), to store the states of flows in the on-chip memory at networking devices (Bonomi et al,2006)
4. CUCKOO SEARCH
Cuckoo search is an optimization algorithm inspired by the brood parasitism of cuckoo species by laying their eggs in the nests of other host birds proposed by Yang and Deb (2009). If a host bird discovers the eggs are not their own, it will either throw these foreign eggs away or simply abandon its nest and build a new nest elsewhere. Each egg in a nest represents a solution, and a cuckoo egg represents a new solution. The better new solution (cuckoo) is replaced with a solution which is not so good in the nest. In the simplest form, each nest has one egg. When generating a new solution Levy flight is performed. The rules for CS are described as follows:
? Each cuckoo lays one egg at a time, and dumps it in a randomly chosen nest ? The best nests with high quality of eggs will carry over to the next generations; ? The number of available host nests is fixed, and a host can discover an foreign egg with a probability p a ?[0, 1]. In this case, the host bird can either throw the egg away or abandon the nest so as to build a completely new nest in a new location
The algorithm for CS is given below:
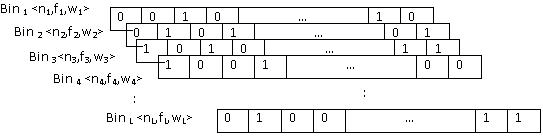
Generate an initial population of n host nests; not belong to the set. In order to store a given element into the bit array, each hash function must be applied to it and, based on the return value r of each function (r1, r2, ? , rk), the bit with the offset r is set to 1. Since there are k hash functions, up to k bits in the bit array are set to 1 (it might be less because several hash functions might return the same value). Figure 1 is an example where m=16, k=4 and e is the element to be stored in the bit array. A BBF is a date structure considering weight for spam word. It groups spam words into different bins depending on their weight. It incorporates the information on the spam word weights and the membership likelihood of the spam words into its optimal design. In BBF a high cost bin lower false positive probability and a low cost bin has higher false positive probability. The false positive rate and number of strings to be stored is identified through optimization technique GA which minimize the total membership invalidation cost. Figure 2 shows Bin BF with its tuple <n,f,w> configuration.
5. Evaluate its fitness Fi
The objective function f(L) taken as standard for the problem of minimization is
? ? ? ? < ? = max max max C F( L) if 0 C F( L) if F( L) C f( L) (5)where Cmax is a large constant.
which has an infinite variance with an infinite mean. Here the consecutive jumps of a cuckoo essentially form a random walk process which obeys a power-law step-length distribution with a heavy tail. The representation of egg (solution) is given in figure 3.
where nij, fij and wij refer respectively the number of words, false positive rate of and the weight of the jth bin of ith egg. The triplet <n,f,w> encodes a single bin. The false positive rate fij can be obtained from equation (1) where nij is drawn from the ith egg in the nest, m is known in advance and k is calculated from equation (3). One egg in the nest represents one possible solution for assigning the triples <n, f, w>. At the initial stage, each egg randomly chooses different <n, f, w> for L Bins based on the given constraints. The fitness function for each egg can be calculated based on the equation (5).
6. VII. EXPERIMENTAL RESULTS
Cuckoo Search employs Levy flight for finding new solutions from equation (7). CS and ECS consider 10 nests and 50 iterations. The parameters pa,? and ? are set as 0.3, 1 and 1.5 respectively. The total number of strings taken for testing is 250, 500, and 1000. The string weights are varying from 0.0005 to 5. The size of the BF is 1024. This experimental setup is applied for number of bins from 4 to 7.
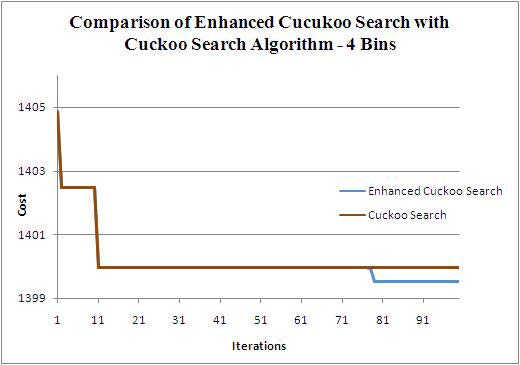
Figures 4a, 4b, 4c and 4d correspondingly show the total membership invalidation cost obtained from BBF for bin sizes from 4 to 7 for 1000 strings using CS and ECS algorithm. In this experimental setup the ECS performs better than CS. Figures 5a, 5b, 5c and 5d show the total membership invalidation cost obtained from BBF for bin sizes from 4 to 7 respectively for 500 strings. Figures 6a, 6b, 6c and 6d show the cost of BBF from bin sizes 4 to 7 for 250 strings. For all the string sizes the ECS outperforms CS.
In CS, 10 nests which equals to number of nests in ECS and 40 nests which equals to number of eggs in ECS are taken to find the total membership invalidation cost for 1000 strings. Figure 7 shows the total membership invalidation cost obtained from BBF for the bin sizes ranging from 4 to 10 using CS and ECS. It shows that the cost is decreased when the numbers of bins are increased. The results obtained from ECS outperform CS for all bin sizes from 4 to 10.
(A) (B)

![Choose a nest among n (say, j) randomly; if (Fi > Fj),[for maximization] Replace j by the new solution; end if A fraction (pa) of the worse nests is abandoned and new ones are built; Keep the best solutions/nests; Rank the solutions/nests and find the current best; Pass the current best to the next generation; end while IV. ENHANCED CUCKOO SEARCH FOR BLOOM FILTER OPTIMIZATION a) Bin Bloom Filter (BBF)](https://computerresearch.org/index.php/computer/article/download/434/version/101977/12-An-Enhanced-Cuckoo-Search-for-Optimization_html/34882/image-6.png)


![c) ECS for Optimization of BF The CS is extended to an ECS in which each nest has multiple eggs representing a set of solutions. Generate an initial population of n host nests with m eggs; while (t<MaxGeneration) or (stop criterion) Get a cuckoo randomly (say, i) by Levy flights using the best egg in the chosen nest; Evaluate its fitness Fi Choose a nest among n and choose an egg with the worst solution in the nest (say, j); if (Fi > Fj),[for maximization] An Enhanced Cuckoo Search for Optimization of Bloom Filter in Spam Filtering Global Journal of Computer Science and Technology Volume XII Issue I Version I 77 January 2012 Replace j by the new solution i; end if Find the best solution (among m) in each nest; Rank the nests based on the best solution; Abandon a fraction (pa) of the nests which have worse solutions and built new ones; Keep the best solutions/nests; Rank the solutions/nests and find the current best; end while The symbol ? is an entry-wise multiplication. Basically Levy flights provide a random walk while their random steps are drawn from a Levy distribution for large steps Levy~u = t-?](https://computerresearch.org/index.php/computer/article/download/434/version/101977/12-An-Enhanced-Cuckoo-Search-for-Optimization_html/34885/image-9.png)
| It is applied in networking literature (Brooder and | |
| Mitzenmacher, 2005). A BF can be used as a | |
| summarizing technique to aid global collaboration in | |
| peer-to-peer networks (Kubiatowicz et al., 2000 ; Li et al, | |
| 2002 ; Cuena-Acuna | et al, 2003). It supports |
| probabilistic algorithms for routing and locating | |
| resources (Rhea and Kubiatowicz 2004; Hodes et | |
| al,2002 ; Reynolds and Vahdat, 2003; Bauer et al, 2004) | |
| and share Web cache information | |