1. INTRODUCTION
ssociation rule mining, introduced in [28], is considered as one of the most important tasks in Knowledge Discovery in Databases [29]. Among sets of items in transaction databases, it aims at discovering implicative tendencies that can be valuable information for the decision-maker. An association rule is defined as the implication X ? Y, described by two interestingness measures support and confidence, where X and Y are the sets of items and X ? Y = ? .
Apriori [28] is the first algorithm proposed in the association rule mining field and many other algorithms were derived from it. It is very well known that mining algorithms can discover a prohibitive amount of association rules; Starting from a database, it proposes to extract all association rules satisfying minimum thresholds of support and confidence. For instance, thousands of rules are extracted from a database of several dozens of attributes and several hundreds of transactions. Furthermore, as suggested by Silbershatz and Tuzilin [30], valuable information is often represented by those rare low support and unexpected association rules which are surprising to the user. So, the more we increase the support threshold, the more efficient the algorithms are and the more the discovered rules are obvious, and hence, the less they are interesting for the user. As a result, it is necessary to bring the support threshold low enough in order to extract valuable information. Unfortunately, the lower the support is, the larger the volume of rules becomes, making it intractable for a decision-maker to analyze the mining result. Experiments show that rules become almost impossible to use when the number of rules overpasses 100. Thus, it is crucial to help the decisionmaker with an efficient technique for reducing the number of rules.
To overcome this drawback, several methods were proposed in the literature. On the one hand, different algorithms were introduced to reduce the number of itemsets by generating closed [31], maximal [32] or optimal itemsets [33], and several algorithms to reduce the number of rules, using non redundant rules [34], [35], or pruning techniques [36]. On the other hand, post processing methods can improve the selection of discovered rules. Different complementary post processing methods may be used, like pruning, summarizing, grouping, or visualization [37]. Pruning consists in removing uninteresting or redundant rules. In summarizing, concise sets of rules are generated. Groups of rules are produced in the grouping process, and the visualization improves the readability of a large number of rules by using adapted graphical representations.
However, most of the existing post processing methods are generally based on statistical information in the database. Since rule interestingness strongly depends on user knowledge and goals, these methods do not guarantee that interesting rules will be extracted. In this paper, we propose a novel framework to identify closed itemsets. Associations are discovered based on inference analysis. The principle of the approach considers that an association rule should only be reported when there is enough interest gain claimed during inference analysis in the data. To do this, we consider both presence and absence of items during the mining. An association such as beer ? nappies will only be reported if we can also find that there are fewer occurrences of ¬ beer ? nappies nappies. This approach will ensure that when a rule such as beer ? nappies is reported, it indeed has the strongest interest in the data as comparison was made on both presence and absence of items during the mining process.
2. II.
3. RELATED WORK
The sequential item set mining problem was initiated by Agrawal and Srikant, and the same was developed as a filtered algorithm, GSP [2], basing on the Apriori property [19]. Since then, lots of sequential item set mining algorithms are being developed for efficiency. Some are, SPADE [4], Prefixspan [5], and SPAM [6]. SPADE is on principle of vertical id-list format and it uses a lattice-theoretic method to decompose the search space into many tiny spaces, on the other hand Prefixspan implements a horizontal format dataset representation and mines the sequential item sets with the pattern-growth paradigm: grow a prefix item set to attain longer sequential item sets on building and scanning its database. The SPADE and the Prefixspan highly perform GSP. SPAM is a recent algorithm used for mining lengthy sequential item sets and implements a vertical bitmap representation. Its observations reveal, SPAM is better efficient in mining long item sets compared to SPADE and Prefixspan but, it still takes more space than SPADE and Prefixspan. Since the frequent closed item set mining [15], many capable frequent closed item set mining algorithms are introduced, like A-Close [15], CLOSET [20], CHARM [16], and CLOSET+ [18]. Many such algorithms are to maintain the ready mined frequent closed item sets to attain item set closure checking. To decrease the memory usage and search space for item set closure checking, two algorithms, TFP [21] and CLOSET+2, implement a compact 2-level hash indexed result-tree structure to keep the readily mined frequent closed item set candidates. Some pruning methods and item set closure verifying methods, initiated that can be extended for optimizing the mining of closed sequential item sets also. CloSpan is a new algorithm used for mining frequent closed sequences [17]. It goes by the candidate maintenance-and-test method: initially create a set of closed sequence candidates stored in a hash indexed result-tree structure and do post-pruning on it. It requires some pruning techniques such as Common Prefix and Backward Sub-Item set pruning to prune the search space as CloSpan requires maintaining the set of closed sequence candidates, it consumes much memory leading to heavy search space for item set closure checking when there are more frequent closed sequences. Because of which, it does not scale well the number of frequent closed sequences. BIDE [26] is another closed pattern mining algorithm and ranked high in performance when compared to other algorithms discussed. BIDE projects the sequences after projection it prunes the patterns that are subsets of current patterns if and only if subset and superset contains same support required. But this model is opting to projection and pruning in sequential manner. This sequential approach sometimes turns to expensive when sequence length is considerably high. In our earlier literature [27] we discussed some other interesting works published in recent literature.
4. III.
5. DATASET ADOPTION AND FORMULATION
Item Sets 'I': A set of diverse elements by which the sequences generate.
6. ?
Represents a sequence 's' of items those belongs to set of distinct items 'I', 'm' is total ordered items and P(e i ) is a transaction, where e i usage is true for that transaction. S: represents set of sequences, 't' represents total number of sequences and its value is volatile and s j : is a sequence that belongs to S.
Subsequence: is a sequence p s of sequence set 'S' is considered as subsequence of another sequence q s of Sequence Set 'S' if all items in sequence S p is belongs to s q as an ordered list. This can be formulated as
If 1 ( ) ( ) n pi q p q i s s s s = ? ? ? ? Then 1 1 : n m pi qj i j s s = = < ? ? where p q s S7. CLOSED ITEMSET DISCOVERY a) PEPP: Parallel Edge Projection and Pruning Based
Sequence Graph protrude [28] i. Preprocess:
As a first stage of the proposal we perform dataset preprocessing and itemsets Database initialization. We find itemsets with single element, in parallel prunes itemsets with single element those contains total support less than required support.
ii. Forward Edge Projection:
In this phase, we select all itemsets from given itemset database as input in parallel. Then we start projecting edges from each selected itemset to all possible elements. The first iteration includes the pruning process in parallel, from second iteration onwards this pruning is not required, which we claimed as an efficient process compared to other similar techniques like BIDE. In first iteration, we project an itemset p s that spawned from selected itemset i s from
8. b) Description of Inference Analysis
Set I = {i1, i2? im} be the universe of items composed of m different attributes, ik(k=1,2,...,m) is item. Transaction database D is a collection of transaction T, A transaction t = (tid, X) is a tuple where tid is a unique transaction ID and X is an itemset. The count of an itemset X in D, denoted by count(X), is the number of transactions in D containing X. The support of an itemset X in D, denoted by supp(X), is the proportion of transactions in D that contain X. The negative rule X?¬Y holds in the transaction set D with confidence conf
(X?¬Y) = supp ( ) X Y ? ¬ /supp (X).In Transaction database, each transaction is a collection of items involved sequences. The issue of mining association rules is to get all association rules that its support and confidence is respectively greater than the minimum threshold given by the user. The issues of mining association rules can be divide into two sub-issues as follows:
Find frequent itemsets, Generate all itemsets that support is greater than the minimum support. Generate association rules from frequent itemsets. In logical analysis, the direct calculation of support is not convenient, To calculate the support and confidence of negative associations using the support and confidence
9. VI. COMPARATIVE STUDY
This segment focuses mainly on providing evidence on asserting the claimed assumptions that 1) The PEPP is similar to BIDE which is actually a sealed series mining algorithm that is competent enough to momentously surpass results when evaluated against other algorithms such as CloSpan and SPADE. 2) Utilization of memory and momentum is rapid when compared to the CloSpan algorithm which is again analogous to BIDE. 3) There is the involvement of an enhanced occurrence and a probability reduction in the memory exploitation rate with the aid of the trait equivalent prognosis and also rim snipping of the PEPP with inference analysis for no coherent pattern pruning. This is on the basis of the surveillance done which concludes that PEPP's implementation is far more noteworthy and important in contrast with the likes of BIDE, to be precise.
JAVA 1.6_ 20th build was employed for accomplishment of the PEPP and BIDE algorithms. A workstation equipped with core2duo processor, 2GB RAM and Windows XP installation was made use of for investigation of the algorithms. The parallel replica was deployed to attain the thread concept in JAVA.
10. VII.
11. DATASET CHARACTERISTICS
Pi is supposedly found to be a very opaque dataset, which assists in excavating enormous quantity of recurring clogged series with a profitably high threshold somewhere close to 90%. It also has a distinct element of being enclosed with 190 protein series and 21 divergent objects. Reviewing of serviceable legacy's consistency has been made use of by this dataset. Fig. 5 portrays an image depicting dataset series extent status.
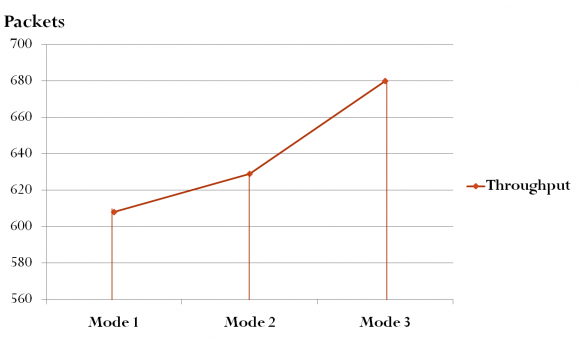
In assessment with all the other regularly quoted forms like SPADE, prefixspan and CloSpan, BIDE has made its mark as a most preferable, superior and sealed example of mining copy, taking in view the detailed study of the factors mainly, memory consumption and runtime, judging with PEPP. In contrast to PEPP and BIDE, a very intense dataset Pi is used which has petite recurrent closed series whose end to end distance is less than 10, even in the instance of high support amounting to around 90%. The diagrammatic representation displayed in Fig 3 explains that the above mentioned two algorithms execute in a similar fashion in case of support being 90% and above. But in situations when the support case is 88% and less, then the act of PEPP surpasses BIDE's routine. The disparity in memory exploitation of PEPP and BIDE can be clearly observed because of the consumption level of PEPP being lower than that of BIDE. The concept inference analysis we introduced here played a vital role in closed itemset detection. The significant improvement in closed itemset detection can be observable in our results, see the fig 6 . VIII.
12. CONCLUSION
It has been scientifically and experimentally proved that clogged prototype mining propels dense product set and considerably enhanced competency as compared to recurrent prototype of mining even though both these types project similar animated power. The detailed study has verified that the case usually holds true when the count of recurrent moulds is considerably large and is the same with the recurrent bordered models as well. However, there is the downbeat in which the earlier formed clogged mining algorithms depend on chronological set of recurrent mining outlines. It is used to verify whether an innovative recurrent outline is blocked or else if it can nullify few previously mined blocked patterns. This leads to a situation where the memory utilization is considerably high but also leads to inadequacy of increasing seek out space for outline closure inspection. This paper anticipates an unusual algorithm for withdrawing recurring closed series with the help of Sequence Graph. It performs the following functions: It shuns the blight of contender's maintenance and test exemplar, supervises memory space expertly and ensures recurrent closure of clogging in a well-organized manner and at the same instant guzzling less amount of memory plot in comparison with the earlier developed mining algorithms. There is no necessity of preserving the already defined set of blocked recurrences, hence it very well balances the range of the count of frequent clogged models. A Sequence graph is embraced by PEPP and has the capability of harvesting the recurrent clogged pattern in an online approach. The efficacy of dataset drafts can be showcased by a wide-spread range of experimentation on a number of authentic datasets amassing varied allocation attributes. PEPP is rich in terms of velocity and memory spacing in comparison with the BIDE and CloSpan algorithms. ON the basis of the amount of progressions, linear scalability is provided. It is also proven that PEPP is efficient to find closed itemsets under inference analysis. It has been proven and verified by many scientific research studies that limitations are crucial for a number of chronological outlined mining algorithms. In addition we improved closed itemset detection performance by introducing inference analysis as an extension to PEPP. Future studies include proposing of post processing and pruning of the rules based on categorical relations between attributes.




| ( ) ts t f s : ( ) ( ) | | ts t qs t S f s f s DB = | |||||||
| Sub-sequence | and | Super-sequence: | A | ||||
| sequence is sub sequence for its next projected | |||||||
| ovember N | sequence if both sequences having same total support. Super-sequence: A sequence is a super sequence for a sequence from which that projected, if both having same total support. Sub-sequence and | ||||||
| super-sequence can be formulated as | |||||||
| If threshold given by user And ( ) ts t f s ? rs where 'rs' is required support : t p s s for any p value < | |||||||
| where | ( ) t f s ts | ? | ( ) p f s ts | ||||
| IV. | |||||||
| ? | and s S ? | ||||||
| Total Support 'ts' : occurrence count of a | |||||||
| sequence as an ordered list in all sequences in | |||||||
| sequence set 'S' can adopt as total support 'ts' of that | |||||||
| sequence. Total support 'ts' of a sequence can | |||||||
| determine by fallowing formulation. | |||||||
| ( ) | t f s ts = < : ( t p s s for each p | 1.. | = |) | S DB | ||||||
| L3: For each projected Itemset p s in memory | iii. Edge pruning: | ||||||||||||
| Begin: | If any of | ' ( ) p f s ts | ? | ( ) p f s ts | that edge will be | ||||||||
| s | p | ' | = | s | p | pruned and all disjoint graphs except | p s will be | ||||||
| L4: For each i e of 'I' | considered as closed sequence and moves it into and remove all disjoint graphs from memory. | S DB | |||||||||||
| Begin: | The above process continues till the elements | ||||||||||||
| Project p s from C2: If ( ) ts p f s ? | ' ( , ) p i s e rs | available in memory those are connected through direct or transitive edges and projecting itemsets i.e., till graph become empty. | |||||||||||
| Begin Spawn SG by adding edge between ' p s and e i End: C2 End: L4 C3: If ' s not spawned and no new projections added p for ' p s Begin: | b) Inference Analysis: Inferences:-a. Pattern positive score is sum of no of transactions in which all items in the pattern exist, no. of transactions in which all items in the pattern does not exist. b. Pattern negative score is no of transactions in which only few items of the pattern exist. | 2011 November 3 | |||||||||||
| Remove all duplicate edges for each edge | c. Pattern actual coverage is pattern positive score- | ||||||||||||
| weight from ' | pattern negative score. | ||||||||||||
| d. Interest gain is Actual coverage of the pattern | |||||||||||||
| involved in association rule. | |||||||||||||
| e. Coherent rule Actual coverage of the rule's left side | |||||||||||||
| pattern must be greater than or equal to actual | |||||||||||||
| coverage of the right side pattern. | |||||||||||||
| f. Inference Support ia s refers actual coverage of the | |||||||||||||
| pattern. | |||||||||||||
| g. | ( ) t f s Represents the inference support of the ia | ||||||||||||
| sequence s t. | |||||||||||||
| V. | Approach | ||||||||||||
| For each pattern s p of the pattern dataset, If | |||||||||||||
| ( ) ia t f s | < | ia | s | then we prune that pattern | |||||||||
| a) PEPP 1 Algorithm: | |||||||||||||
| This section describes algorithms for initializing | |||||||||||||
| sequence database with single elements sequences, | |||||||||||||
| spawning itemset projections and pruning edges from | |||||||||||||
| Sequence Graph SG. | |||||||||||||
| Input: | S DB and 'I'; | ||||||||||||
| S DB and an element i e considered from 'I'. If the ( ) ts p f s is greater or equal to rs , then an edge will be defined between i s and i e . If ( ) ( ) ts i ts p f s f s ? then we prune i s from S DB . This pruning process required and limited to first iteration only. From second iteration onwards project the itemset p S that spawned from ' p S to each element i e of | L1: For each sequence i s in Begin: L2: For each element i e of 'I' DB S Begin: C1: if edgeWeight( , ) i i s e rs ? Begin: Create projected itemset p s from ( , ) i i s e | ||||||||||||
| 'I'. An edge can be defined between ( ) | ' S and i p e if | If | ( ) i f s ts | ? | ( ) p f s ts | then prune i s from | S DB | ||||||
| End: C1. | |||||||||||||
| End: L2. | |||||||||||||
| End: L1. | |||||||||||||